|
Gaussian 03
La ejecución de Gaussian (tanto en su versión 03 como 98) en los servidores del CESGA, representa cerca de un 70% del consumo de horas de computación en el periodo 1 de enero de 2004 a 30 de septiembre de 2004, principalmente desde su instalación en el nuevo HP Superdome. La incorporación de Gaussian 03 (http://www.gaussian.com), con nuevas funcionalidades, más adaptada a las arquitecturas existentes en el CESGA, representa un cambio tecnológico importante en la aplicación. En esta nueva versión se cambia el sistema de paralelización, pasando a la utilización de hilos (threads en inglés) a través del estándar OpenMP (http://www.openmp.org). Esto significa, por ejemplo, que ya no utiliza memoria compartida, ya que todos los hilos pueden acceder a la memoria reservada por el programa directamente. Se mantiene la posibilidad de ejecución de multiproceso a través de LINDA (http://www.lindaspaces.com/products/linda.html), pero esta funcionalidad no está disponible en ningún servidor del CESGA.
Fig. 1. Porcentaje de horas de uso de CPU.
Dada la importancia que tiene la utilización de este software en el CESGA, es importante conocer adecuadamente la forma de mejorar el rendimiento, de tal forma que se optimice el uso conjunto e individual de los servidores. Por ello se ha analizado el comportamiento del Gaussian para algunos de los problemas tipo habituales, en función de los parámetros más importantes que pueden ser seleccionados por el usuario: la memoria a utilizar y el número de hilos (o procesadores). Este análisis solo se realiza para Gaussian 03. Si se necesita la misma información para Gaussian 98, consulte la página Web http://www.cesga.es/ga/CalcIntensivo/gaussian98.html.
1. Utilización de la memoria
La selección de memoria virtual a utilizar en la ejecución de un problema se fija a través de la directiva %MEM. Ésta ha de estar situada antes de cada link que se incluya en el fichero. En caso de que no se fije, Gaussian reservará por defecto 6 MegaWords (6 millones de palabras, donde cada palabra corresponde a 8 Bytes). La sintaxis de este comando es
%mem=<numero><unidad>
donde número es la cantidad de memoria a utilizar (en el ejemplo 6) y unidad puede ser KB, MB, GB (cuando la cantidad se expresa en Bytes) ó KW, MW, GW (cuando se expresa en palabras. Una palabra equivale a 8 bytes en el HPC320 y SUPERDOME). Por ejemplo:
%mem=6mw
#P HP/ST0-3G FORCE
En función del tipo de problema y de la memoria seleccionada, Gaussian elige el modo de funcionamiento de forma automática que considera más adecuado, a menos que se le especifique lo contrario. Los modos de funcionamiento pueden ser:
- Directo. Todas las integrales necesarias para la resolución son calculadas cuando se necesitan. Es el modo por defecto.
- Convencional. Las integrales se calculas una vez y se acumulan en disco. Este sistema es más lento que el directo, por lo cual está desaconsejado
- InCore. Las integrales necesarias se acumulan en memoria (cuidado, si se selecciona este método de cálculo, si no hay suficiente memoria el cálculo no se ejecutará).
- Semi-directo. Fundamentalmente utilizado en cálculos MP. Es una combinación del modo directo con el convencional.
Para hacer una estimación de la memoria mínima necesaria para un cálculo, se ha de utilizar la fórmula
M + 2 Nb2
Que dará la cantidad de memoria en palabras. Nb es el número de bases del problema, mientras que M es una cantidad dependiente del mismo que se ha de seleccionar de la tabla dada en el manual (http://www.gaussian.com/g_ur/m_eff.htm):
|
Job Type
|
Highest Angular Momentum Basis Function
|
|
f functions
|
g functions
|
h functions
|
i functions
|
j functions
|
|
SCF Energies
|
4 MW
|
4 MW
|
9 MW
|
23 MW
|
~60 MW
|
|
SCF Gradients
|
4 MW
|
5 MW
|
16 MW
|
38 MW
|
|
|
SCF Frequencies
|
4 MW
|
9 MW
|
27 MW
|
|
|
|
MP2 Energies
|
4 MW
|
5 MW
|
10 MW
|
28 MW
|
~70 MW
|
|
MP2 Gradients
|
4 MW
|
6 MW
|
16 MW
|
38 MW
|
|
|
MP2 Frequencies
|
6 MW
|
10 MW
|
28 MW
|
|
|
Para el caso de un problema de cálculo de frecuencias, existe además la utilidad freqmem que calcula la memoria mínima en función del tipo de problema y número de átomos.
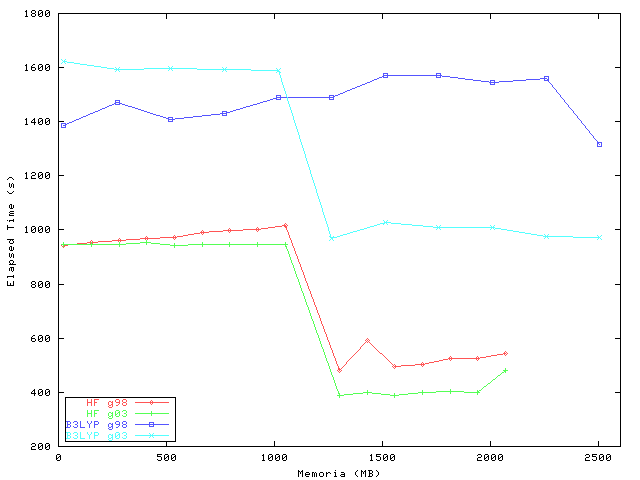
Fig.2 . Tiempos de cálculo versus la memoria disponible para 188 bases.
Sin embargo, existe una fuerte dependencia de la velocidad del cálculo con el tipo de método que depende fundamentalmente de la memoria disponible. Por ejemplo, se puede apreciar en la fig. 2 que para un cálculo DFT ó HF, incrementar la reserva de memoria por encima del mínimo necesario no ayuda a mejorar la velocidad del mismo (de hecho en Gaussian 98, la eficiencia del mismo disminuye de forma apreciable), por lo que se estarían desperdiciando recursos innecesariamente. Sin embargo, esta situación cambia cuando la cantidad reservada es suficiente para acumular las integrales en memoria; cuando Gaussian cambia el método de resolución a InCore. La mejora en el rendimiento es sustancial en este caso (cercano al 100%).
Para poder calcular la memoria necesaria en Gaussian 03 para realizar el problema utilizando el método InCore, se pueden utilizar las fórmulas:
Nb4/8 + 500.000 para el caso de Close-Shell
Nb4/4 + 500.000 para el caso de UHF ó ROHF
Que también se pueden aplicar para los métodos GVB y MCSCI.
Fig. 3. Consumo de memoria de DFT versus el número de bases.
En la figura 3 se puede ver el consumo de memoria para un problema DFT con respecto a las dos fórmulas. Se aprecia que la primera fórmula es un límite máximo para todos los casos. Para asegurarse de que se utiliza el cálculo en forma Incore, se pueden utilizar los comandos SCF=Incore para el caso DFT ó HF, mientras que para otros es necesario especificarlo directamente (véase el manual para cada caso). Por ejemplo, para MP2 el cálculo se realizaría InCore con el comando MP2=Incore.
2. Ejecución en paralelo.
Como ya se dijo anteriormente, Gaussian 03 utiliza la tecnología OpenMP (única posibilidad existente en el CESGA) o memoria distribuida (es decir, varios procesos que no comparten memoria, a través de LINDA, no disponible en el CESGA). En la versión actual, entre los enlaces (links) paralelizados están:
| Link |
Descripción
|
| L502 |
Solución de la ecuación SCF iterativa
|
| L703 |
Derivadas primera y segunda (spdf)
|
| L914 |
Estados excitados de CI-singles, RPA y Zindo. Estabilidad SCF
|
| L1002 |
Solución de las ecuaciones CPHF; cálculo de propiedades (como NMR)
|
| L1110 |
Contribución de las integrales de 2e a Fx
|
En general, teniendo en cuenta esto, todos los cálculos de energía, gradientes y frecuencia a través de SCF (esto es, HF, DFT y CIS) junto con TD-DFT están paralelizados. Otros métodos, como Möller-Plesset, no mejoran suficientemente cuando se ejecuta con más de un procesador utilizando hilos, por lo que se desaconseja su uso en esos casos.
Para ejecutar Gaussian en paralelo, se ha de utilizar la nueva clave
%NprocShared
Por ejemplo, para la ejecución con cuatro hilos, se utilizaría
%NProcShared=4
Es importante notar que para que esto sea eficiente y que cada hilo se pueda ejecutar de forma independiente en un procesador dedicado, es necesario solicitarlo también en la petición del trabajo a través de la directiva num_proc del comando qsub. Si no se hiciera así, Gaussian crearía igualmente 4 hilos, compitiendo ellos mismos por el uso del procesador y por lo tanto degradando el rendimiento.
Para ejecutar con más de un procesador es necesario tener en cuenta que:
1. La memoria mínima necesaria cuando el cálculo se realiza de forma directa se incrementa (Gaussian recomienda multiplicar la memoria mínima calculada de la forma anterior por el número de hilos a utilizar).
2. Cuando el cálculo se puede hacer InCore, la memoria adicional necesaria es insignificante, aunque es necesario aumentarla un poco con respecto a la prevista para el cálculo.
Fig. 4: Tiempos de cálculo para un problema DFT y HF directo e incore. El escalado se define como la razón entre el tiempo consumido para 1 procesador dividido entre el tiempo para n procesadores. La eficiencia es el escalado dividido por el número de procesadores.
En la figura 4 se puede ver el comportamiento paralelo de dos métodos de uso habitual. Se puede observar que en ambos casos se reduce en tiempo de cálculo, mejorando sensiblemente en el caso directo, alcanzando para cuatro procesadores un rendimiento casi idéntico. Existe una dependencia entre la eficiencia de la paralelización con el número de bases (en realidad con el número de primitivas); a mayor número de bases, mejor eficiencia de la paralelización. Esto es debido a que el programa está más fracción del tiempo ejecutando zonas de código paralelizadas.
3. Paso de integrales al cálculo de frecuencias.
El cálculo de frecuencias puede mejorar sensiblemente con la memoria. Para calcular la memoria necesaria se puede utilizar el comando freqmem comentado anteriormente (que proporciona un valor exacto) o estimarla utilizando la fórmula siguiente para calcular el número de palabras
3NANb2 + 500.000
donde NA es el número de átomos y Nb el número de bases.
Si el problema admite la ejecución incore, es posible pasar el resultado de este cálculo al módulo de frecuencias a través del comando SFC=(InCore, pass), a costa de consumir más espacio en disco (del orden de Nb4/8).
4. Matrices Sparse
Cuando el problema es demasiado grande para acumular las integrales completas en memoria, es posible utilizar el método de matrices sparse, a costa de eliminar del cálculo las interacciones con un valor inferior a uno dado (10-10 por defecto). En este caso, solo los valores por encima del de corte se mantienen en memoria. Gaussian recomienda utilizar solo este método cuando el problema tiene más de 400 átomos (200 para cálculos semiempíricos como el AM1). Sin embargo, dado que el consumo de memoria depende de las interacciones calculadas, no es posible a priori calcular la memoria que será necesaria. En caso de que se quiera utilizar este método, es necesario indicarlo en la descripción del problema con la clave sparse (http://www.gaussian.com/g_ur/k_sparse.htm).
5. Reinicio del trabajo.
Dadas la limitaciones de tiempo de ejecución existentes, es posible que algún cálculo no termine adecuadamente por esa limitación. Para reiniciarlo desde el último link que se ha ejecutado es necesario hacer varias acciones. La primera es que se ha de solicitar al final del trabajo la copia de los ficheros al directorio local. Por defecto, estos se crean en el directorio temporal (y por cuestiones de eficiencia, procure no cambiar los ficheros rwf fuera de esta localización). Para ello, al enviar el trabajo al sistema de colas incluya la opción al comando qsub:
-v COPIA=$HOME/destino
De este modo, la copia de los ficheros del directorio temporal se realizará al finalizar el trabajo de forma inesperada. Por ejemplo, supongamos que se envía el trabajo siguiente:
#p rhf/6-311g* opt freq test geom=modela scf=direct
water with restart
0,1
o h h
con las siguientes opciones de qsub
qsub -l num_proc=1,s_rt=00:00:03,s_vmem=500M,h_fsize=1G -cwd -v COPIA=$PWD -o 1.log -e 1.err
Una vez pasados tres segundos de ejecución (tiempo límite marcado en la petición), el trabajo abortaría en el link en donde se está ejecutando de forma abrupta. Al haber solicitado la copia de los ficheros generados en el scratch, se tendrá en el directorio de envío los siguientes ficheros:
total 38658
drwxr-xr-x 2 agomez cesga 1024 Oct 6 13:39 .
drwxr-xr-x 32 agomez cesga 2048 Sep 29 11:45 ..
-rw-r--r-- 1 agomez cesga 107 Oct 6 13:38 1.com
-rw-r--r-- 1 agomez cesga 0 Oct 6 13:39 1.err
-rw-r--r-- 1 agomez cesga 27571 Oct 6 13:39 1.log
-
-rw------- 1 agomez cesga 111 Oct 6 13:38 Gau-7855.inp
-rw------- 1 agomez cesga 532480 Oct 6 13:38 Gau-7860.chk
-rw------- 1 agomez cesga 0 Oct 6 13:38 Gau-7860.d2e
-rw------- 1 agomez cesga 0 Oct 6 13:38 Gau-7860.int
-rw------- 1 agomez cesga 18653184 Oct 6 13:38 Gau-7860.rwf
-rw------- 1 agomez cesga 532480 Oct 6 13:38 Gau-7860.scr
Para rearrancar el trabajo, hay que indicar a Gaussian que utilizamos el fichero RWF correspondiente, para lo cual se definirá el siguiente fichero de comandos de Gaussian:
%rwf=Gau-7860
#p restart
Relanzando el trabajo con esta opción, Gaussian continuará a partir del último link que se haya ejecutado completamente antes de la interrupción. Por ejemplo, en el caso de ejemplo, el último link ejecutado en el primer envío era el l301.exe, estando en ejecución el l302. Al rearrancar, Gaussian reinicia en el link l302 que no había terminado.
6. Recomendaciones
Con los resultados previos, se pueden obtener las siguientes conclusiones:
1. Para cálculos HF, DFT, TD-DFT y CIS, si la memoria necesaria para hacer el cálculo utilizando el método InCore es inferior o igual a 16GB (aunque G03 pueda utilizar más, ya que no existe la limitación que había en G98), intente utilizar este método. Si además es posible paralelizar el cálculo, calcule el número de procesadores como la razón entre la memoria necesaria en GB dividida por 4, con un límite de 4 CPUs para Incore. Tenga en cuenta que cuantos más procesadores solicite, el tiempo de espera para ejecutar el trabajo se incrementa, ya que es necesario que estén disponibles al mismo tiempo.
2. No utilice varios procesadores para métodos combinados como G3 o para cálculos Möller-Plesset, ya que la ganancia es insignificante (si necesita hacer cálculos MP en paralelo, evalúe la posibilidad de utilizar otros programas, como NWCHEM, que sí tienen paralelizada esta opción).
3. Al enviar el trabajo a cola, asegúrese de seleccionar los parámetros adecuados. En la opción s_vmem del comando qsub, incluya la memoria que haya calculado más 200MB (para el código del programa).
4. Si su problema necesita más de 16GB para calcular utilizando el método Incore, compruebe si es paralelizable y utilice preferentemente esta opción con un cálculo directo.
5. Intente enviar siempre la ejecución con la opción de copia de ficheros. En caso de que el trabajo funcione correctamente no obtendrá ninguna salida adicional, ya que Gaussian elimina los ficheros temporales cuando termina correctamente mientras que si termina de forma incorrecta, podrá reiniciar el trabajo desde el último link ejecutado correctamente.
En cualquier caso, si tiene cualquier duda o sugerencia, no dude en contactar con nosotros a través  . . |




















 cesga.es
:: Telf.: +34 981 569810 - Fax: 981 594616 ::
Avda. de Vigo s/n 15705, Santiago de Compostela.
cesga.es
:: Telf.: +34 981 569810 - Fax: 981 594616 ::
Avda. de Vigo s/n 15705, Santiago de Compostela.
{kind=link}